Introduction
SpECTRE builds a layer on top of Charm++ that performs various safety checks and initialization for the user that can otherwise lead to difficult-to-debug undefined behavior. The central concept is what is called a Parallel Component. A Parallel Component is a struct with several type aliases that is used by SpECTRE to set up the Charm++ chares and allowed communication patterns. Parallel Components are input arguments to the compiler, which then writes the parallelization infrastructure that you requested for the executable. There is no restriction on the number of Parallel Components, though practically it is best to have around 10 at most.
Here is an overview of what is described in detail in the sections below:
- Metavariables: Provides high-level configuration to the compiler, e.g. the physical system to be simulated.
- Phases: Defines distinct simulation phases separated by a global synchronization point, e.g. Initialization, Evolve and Exit.
- Algorithm: In each phase, repeatedly iterates over a list of actions until the current phase ends.
- Parallel component: Maintains and executes its algorithm.
- Action: Performs a computational task, e.g. evaluating the right hand side of the time evolution equations. May require data to be received from another action potentially being executed on a different core or node.
The Metavariables Class
SpECTRE takes a different approach to input options passed to an executable than is common. SpECTRE not only reads an input file at runtime but also has many choices made at compile time. The compile time options are specified by what is referred to as the metavariables. What exactly the metavariables struct specifies depends on the executable, but all metavariables structs must specify the following:
- help: a static constexpr Options::String that will be printed as part of the help message. It should describe the executable and basic usage of it, as well as any non-standard options that must be specified in the metavariables and their current values. An example of a help string for one of the testing executables is: "An executable for testing the core functionality of the Algorithm. ""Actions that do not perform any operations (no-ops), invoking simple ""actions, mutating data in the DataBox, receiving data from other ""parallel components, and out-of-order execution of Actions are all ""tested. All tests are run just by running the executable, no input file ""or command line arguments are required";
- component_list: a tmpl::list of the parallel components (described below) that are to be created. Most evolution executables will have the DgElementArray parallel component listed. An example of a component_list for one of the test executables is: using component_list = tmpl::list<NoOpsComponent<TestMetavariables>,MutateComponent<TestMetavariables>,ReceiveComponent<TestMetavariables>,AnyOrderComponent<TestMetavariables>>;
- using const_global_cache_tags: a tmpl::list of tags that are used to place const items in the GlobalCache. The alias may be omitted if the list is empty.
- using mutable_global_cache_tags: a tmpl::list of tags that are used to place mutable items in the GlobalCache. The alias may be omitted if the list is empty.
- default_phase_order: an array of Parallel::Phase that must contain at least Initialization as the first element and Exitas the last element. Phases are described in the next section.
There are also several optional members:
- input_file: a static constexpr Options::String that is the default name of the input file that is to be read. This can be overridden at runtime by passing the --input-file argument to the executable.
- ignore_unrecognized_command_line_options: a static constexpr bool that defaults to false. If set to true then unrecognized command line options are ignored. Ignoring unrecognized options is generally only necessary for tests where arguments for the testing framework, Catch, are passed to the executable.
Phases of an Execution
Global synchronization points, where all cores wait for each other, are undesirable for scalability reasons. However, they are sometimes inevitable for algorithmic reasons. That is, in order to actually get a correct solution you need to have a global synchronization. SpECTRE executables can have multiple phases, where after each phase a global synchronization occurs. By global synchronization we mean that no parallel components are executing or have more tasks to execute: everything is waiting to be told what tasks to perform next.
Every executable must have at least two phases, Initialization and Exit. The next phase is decided by the member function Parallel::Main<Metavariables>::execute_next_phase. Usually the next phase is determined from the default_phase_order provided by the metavariables. If more complex decision making is desired, various components can send data to Parallel::Main via the PhaseControl infrastructure. This allows the next Phase to be determined dynamically. Here is an example of a default_phase_order member variable:
In contrast, an evolution executable might have phases Initialization, SetInitialData, Evolve, and Exit. The first phase that is entered is always Initialization. During the Initialization phase the Parallel::GlobalCache is created, all (node)group components are created, and empty array and singleton components are created. Next, the function allocate_remaining_components_and_execute_initialization_phase is called which allocates singleton components and the elements of each array component, and then starts the Initialization phase on all parallel components. Once all parallel components' Initialization phase is complete, the next phase is determined and the execute_next_phase function is called on all the parallel components.
At the end of an execution the Exit phase has the executable wait to make sure no parallel components are performing or need to perform any more tasks, and then exits. An example where this approach is important is if we are done evolving a system but still need to write data to disk. We do not want to exit the simulation until all data has been written to disk, even though we've reached the final time of the evolution.
If we reach the Exit phase, but some parallel components have not terminated properly, this means a deadlock has occurred. A deadlock usually implies some error in the order messages have been sent/received. For example, if core 0 was paused and waiting to receive a message from core 1, but core 1 was also paused and waiting to receive a message from core 0, this would be considered a deadlock. We detect deadlocks during the Exit phase. All executables have the option to specify a function with the following signature
If this function is specified in the metavariables and a deadlock occurs, this function and all the simple actions in it will run. The information printed during this function call is executable dependent, but it should print enough information for you to determine why the deadlock occurred. If this function isn't specified and a deadlock occurs, a message about how to add this function to your metavariables is printed, but nothing else. After this, the executable aborts.
The Algorithm
Since most numerical algorithms repeat steps until some criterion such as the final time or convergence is met, SpECTRE's parallel components are designed to do such iterations for the user. An Algorithm executes an ordered list of actions until one of the actions cannot be evaluated, typically because it is waiting on data from elsewhere. When an algorithm can no longer evaluate actions it passively waits by handing control back to Charm++. Once an algorithm receives data, typically done by having another parallel component call the receive_data function, the algorithm will try again to execute the next action. If the algorithm is still waiting on more data then the algorithm will again return control to Charm++ and passively wait for more data. This is repeated until all required data is available. The actions that are iterated over by the algorithm are called iterable actions and are described below. Since the action list is phase dependent we refer to them generally as phase-dependent action lists (PDALs, pronounced "pedals").
Parallel Components
Building off the introduction, a Parallel Component is essentially a wrapper around Charm++ chares that makes it easy for a user to add parallel objects into their program. Charm++ chares can be confusing to work with which is why we wrap them. Each parallel component runs its own Algorithm. Data can be sent from one parallel component to another and the receiving parallel components' Algorithm will be able to take that data and continue the program.
1. Types of Parallel Components
There are four types of Parallel Components in SpECTRE:
- Parallel::Algorithms::Singletons have one object in the entire execution of the program. They are implemented as single element Charm++ chare arrays. Charm++ does offer a distributed object called a singleton, however, we explicitly don't use this for various reasons (see Parallel::Algorithms::Singleton). Henceforth and throughout SpECTRE, a singleton will refer to Parallel::Algorithms::Singleton and not a Charm++ singleton.
- Parallel::Algorithms::Arrays hold zero or more elements, each of which is an object distributed to some core. An array can grow and shrink in size dynamically if need be and can also be bound to another array. A bound array has the same number of elements as the array it is bound to, and elements with the same ID are on the same core. See Charm++'s chare arrays for details.
- Parallel::Algorithms::Groups are arrays with one element per core which are not able to be moved around between cores. These are typically useful for gathering data from elements of a Parallel::Algorithms::Array on their core, and then processing or reducing the data further. See Charm++'s group chares for details.
- Parallel::Algorithms::Nodegroups are similar to groups except that there is one element per node. See parallel component placement for the definition of a cores and nodes. We ensure that all entry method calls done through the Algorithm's simple_action and receive_data functions are threadsafe. User-controlled threading is possible by calling the entry method member function threaded_action, which is like simple_action except it passes a node lock to the Action's apply function. Note that unlike simple_actions, multiple threaded_actions can be executing simultaneously on the same chare, but on different cores of the node.
- Note
- Technically there is a fifth type of parallel component called a MainChare which is placed and executed on the global zeroth core. However, there can only be one of these in a executable, it is entirely different from a Singleton, and it is not specifiable by the user so we omit it from the count here.
2. Requirements
Each Parallel Component struct must have the following type aliases:
- using chare_type is set to one of the four types of Parallel Components.
- using metavariables is set to the Metavariables struct that stores the global metavariables. It is often easiest to have the Parallel Component struct have a template parameter Metavariables that is the global metavariables struct. Examples of this technique are given below.
- using phase_dependent_action_list is set to a tmpl::list of Parallel::PhaseActions<Phase, tmpl::list<Actions...>> where each PhaseAction represents a PDAL that will be executed on the parallel component during the specified phase. The Actions are executed in the order that they are given in the tmpl::lists of the PDALs, but the phases need not be run in linear order. However, db::DataBox types are constructed assuming the phases are performed from first in the phase_dependent_action_list to the last. Simple actions (described below) can be executed in any phase. If there are no iterable actions in a phase then a PhaseAction need not be specified for that phase. However, at least one PhaseAction, even if it is empty, must be specified.
- using simple_tags_from_options which is a tmpl::list of all the tags that will be inserted into the initial db::DataBox of each component. These tags are db::SimpleTags that have have a using option_tags type alias and a static function create_from_options (see the example below). This list can usually be constructed from the initialization actions of the component (i.e. the list of actions in the PhaseAction list for the Initialization phase) using the helper function Parallel::get_simple_tags_from_options (see the examples of components below). Each initialization action may specify a type alias using simple_tags_from_options which are a tmpl::list of tags that will be fetched from the db::DataBox by the action.
- using const_global_cache_tags is set to a tmpl::list of tags that are required by the allocate_array function of an array component, or simple actions called on the parallel component. These tags correspond to const items that are stored in the Parallel::GlobalCache (of which there is one copy per Charm++ node). The alias can be omitted if the list is empty.
- using mutable_global_cache_tags is set to a tmpl::list of tags that correspond to mutable items that are stored in the Parallel::GlobalCache (of which there is one copy per Charm++ core). The alias can be omitted if the list is empty.
- array_allocation_tags is set to a tmpl::list of tags that will be constructed from options and will only be used in the allocate_array function of an array component. This type alias is only required for array components.
Additionally, each Parallel Component struct must define a static constexpr bool checkpoint_data, indicating whether the DataBox and inbox contents should be preserved in a checkpoint. Setting this to false is intended for organizational components that only store registration data that can be regenerated during the Restart phase.
- Note
- Array parallel components must also specify the type alias using array_index, which is set to the type that indexes the Parallel Component Array. Charm++ allows arrays to be 1 through 6 dimensional or be indexed by a custom type. The Charm++ provided indexes are wrapped as Parallel::ArrayIndex1D through Parallel::ArrayIndex6D. When writing custom array indices, the Charm++ manual tells you to write your own CkArrayIndex, but we have written a general implementation that provides this functionality (see Parallel::ArrayIndex); all that you need to provide is a plain-old-data (POD) struct of the size of at most 3 integers.
- Note
- Singletons use an array_index of type int, but users need not specify this. It is already specified in the implementation of a singleton.
Parallel array components have a static allocate_array function that is used to construct the elements of the array. The signature of the allocate_array functions must be:
The allocate_array function is called by the Main parallel component when the execution starts and will typically insert elements into array parallel components. If the allocate_array function depends upon input options that are not in the GlobalCache, those tags should be added to the array_allocation_tags type alias. A TaggedTuple is constructed from this type alias and its input options and is only available in the allocate_array function. All other tags that will be constructed from options and used during the Initialization phase should be placed in the simple_tags_from_options type alias. This type alias is a tmpl::list of tags which are db::SimpleTags that have have a using option_tags type alias and a static function create_from_options. They only need to be explicitly added to the list if no initialization action has added them to its simple_tags_from_options type alias. If you want to ignore specific processors when placing array elements, you can pass in a std::unordered_set<size_t> to allocate_array that contains all the processors that shouldn't have array elements on them.
The allocate_array functions of different array components are called in random order and so it is not safe to have them depend on each other.
Each parallel component must also decide what to do in the different phases of the execution. This is controlled by an execute_next_phase function with signature:
Parallel::Main<Metavariables>::execute_next_phase determines the next phase, after which the execute_next_phase function of each component gets called. The execute_next_phase function determines what the parallel component should do during the next phase. Typically the execute_next_phase function should just call start_phase(phase) on the parallel component.
3. Examples
An example of a singleton parallel component is:
An example of an array parallel component is:
There are some parallel components that are common to many executables.
- Parallel::GlobalCache (a Parallel::Algorithms::Nodegroup)
- DgElementArray (a Parallel::Algorithms::Array)
- observers::Observer (a Parallel::Algorithms::Group)
- observers::ObserverWriter (a Parallel::Algorithms::Nodegroup)
The MutableGlobalCache deserves special mention, which is why is has its own section with instructions on how to use it. See Mutable items in the GlobalCache.
4. Placement
The user has some control over where parallel components get placed on the resources it is running on. Here is a figure that illustrates how one may place parallel components.
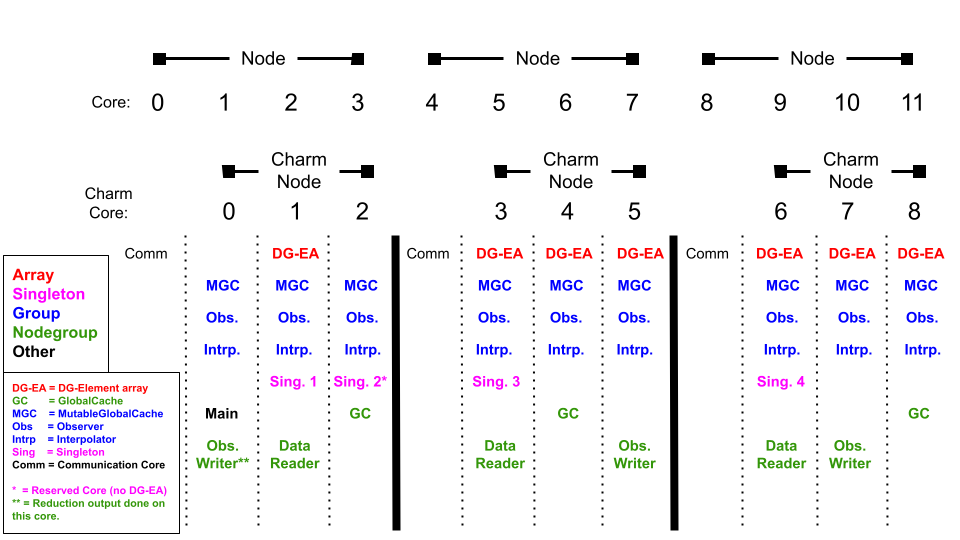
In this example we are running on three (3) nodes that have four (4) cores each. For all our executables, we reserve one core of each node purely for communication purposes. Nothing else is run on this core. Because of this, what Charm++ calls a node, doesn't correspond to a full node on a supercomputer. A charm-node simply corresponds to a collection of cores on a physical node. In our case, a charm-node is represented by the remaining cores on a node not used for communication (i.e. the first charm-node corresponds to cores 1-3 on the first physical node). Also the definition of a charm-core doesn't necessarily have to correspond to an actual core (it could correspond to a hyperthreaded virtual core), however, for our purposes, it does.
SpECTRE offers wrappers around Charm++ functions that will tell you the total number of charm-nodes/cores in an executable and what charm-node/core a parallel component is on. (In the following examples, the type T is an int or a size_t)
- Parallel::my_node<T>() returns the charm-node that the parallel component is on. In the figure, Sing. 4 would return 2.
- Parallel::my_proc<T>() returns the charm-core that the parallel component is on. In the figure, Sing. 4 would return 6 (not 9).
- Parallel::number_of_nodes<T>() returns the total number of charm-nodes in an executable. The above figure would have 3 charm-nodes.
- Parallel::number_of_procs<T>() returns the total number of charm-cores in an executable. The above figure would have 9 charm-cores (not 12).
- Note
- For Charm++ SMP (shared memory parallelism) builds, a node corresponds to a collection of cores on a physical node, and a core corresponds to a processor on that physical node. However, for non-SMP builds, nodes and cores are equivalent. All of our builds are done with Charm++ SMP so nodes and cores have their usual definitions.
The placement of Groups and Nodegroups are determined by Charm++. This is because a Group is on every charm-core and a Nodegroup is on every charm-node. Even though Nodegroups are one per charm-node, the user can't choose which core is used on the charm-node. They run on the next available charm-core on the charm-node.
The Elements of an Array, however, can be placed on specific charm-cores. They are inserted into the Array by using the Charm++ insert member function of the CProxy for the Array. The insert function is documented in the Charm++ manual. In the Array example in the Examples section, array_proxy is a CProxy and so all the documentation for Charm++ array proxies applies. SpECTRE always creates empty arrays with the constructor and requires users to insert however many elements they want and on which charm-cores they want them to be placed. Note that load balancing calls may result in array elements being moved.
In a similar fashion, Singletons can also be placed on specific charm-cores. This can be specified in the input file.
From an input file, there are two ways to specify where Array/Singleton parallel components can be placed.
First is the AvoidGlobalProc0 option. This option will tell the program to not put any Array Elements or Singletons on the global zeroth charm-core. This core is sometimes used to write data to disk which is typically much slower than the program execution. The second is the Singletons: option. You can set the value to Auto, and then each singleton will have their proc be chosen automatically and they won't be exclusive. Otherwise, you must specify options for each singleton as in the example above. AhA is the pretty_type::name() of a Singleton in the program and the user has a choice of which proc to place the Singleton on (Auto will let the program decide) and whether to exclude Array Elements or other Singletons from being put on this core. This is useful in case the Singleton does some expensive computation that shouldn't be slowed down by having lots of Array Elements on the same core. In the figure above, AvoidGlobalProc0 is true, and Sing. 2 requested to be exclusively on core 2.
Actions
Actions are structs with a static apply method and come in five variants: simple actions, iterable actions, reduction actions, threaded actions, and local synchronous actions.
The signature of apply methods differs for the different types of actions, but all types have the same general form. Actions receive a db::DataBox, the Parallel::GlobalCache, and their element's index and parallel component, as well as arguments specific to the action type.
The db::DataBox should be thought of as the member data of the parallel component while the actions are the member functions. The combination of a db::DataBox and actions allows building up classes with arbitrary member data and methods using template parameters and invocation of actions. This approach allows us to eliminate the need for users to work with Charm++'s interface files, which can be error prone and difficult to use.
The Parallel::GlobalCache is passed to each action so that the action has access to global data and is able to invoke actions on other parallel components. The ParallelComponent template parameter is the tag of the parallel component that invoked the action. A proxy to the calling parallel component can then be retrieved from the Parallel::GlobalCache. The remote entry method invocations are slightly different for different types of actions, so they will be discussed below. However, one thing that is disallowed for all actions is calling an action locally from within an action on the same parallel component. Specifically,
Here Parallel::local() is a wrapper around ckLocal() which is a Charm++ provided method that returns a pointer to the local (currently executing) parallel component. See the Charm++ manual for more information. However, you are able to queue a new action to be executed later on the same parallel component by getting your own parallel component from the Parallel::GlobalCache (Parallel::get_parallel_component<ParallelComponent>(cache)). The difference between the two calls is that by calling an action through the parallel component you will first finish the series of actions you are in, then when they are complete Charm++ will call the next queued action.
Array, group, and nodegroup parallel components can have actions invoked in two ways. First is a broadcast where the action is called on all elements of the array:
The second case is invoking an action on a specific array element by using the array element's index. The below example shows how a broadcast would be done manually by looping over all elements in the array:
Note that in general you will not know what all the elements in the array are and so a broadcast is the correct method of sending data to or invoking an action on all elements of an array parallel component.
The array_index argument passed to all apply methods is the index into the parallel component array. If the parallel component is not an array the value and type of array_index is implementation defined and cannot be relied on.
1. Simple Actions
Simple actions can be thought of as member functions of remote objects (chares/parallel components). They are the direct analog of entry methods in Charm++ except that the member data is stored in the db::DataBox that is passed in as the first argument. A simple action must return void but can use db::mutate to change values of items in the db::DataBox if the db::DataBox is taken as a non-const reference. In some cases you will need specific items to be in the db::DataBox otherwise the action won't compile. To restrict which db::DataBoxes can be passed you should use requires in the action's apply function template parameter list. For example,
checks that CountActionsCalled is available in the box.
Simple actions can be called using a CProxy (see the Charm++ manual), which is retrieved from the Parallel::GlobalCache using the parallel component struct and the Parallel::get_parallel_component() function. For example, the action above could be called as
Any arguments after the proxy are passed as additional arguments to the action's apply function.
2. Iterable Actions
Iterable actions make up the algorithms described by the PDALs. These actions are executed one after the other until one of them cannot be evaluated. Their apply methods signature is
The ActionList type is the tmpl::list of iterable actions in the current phase. That is, it is equal to the action_list type alias in the current PDAL. The inboxes is a collection of the tags specified as tmpl::lists in the iterable actions' member type aliases inbox_tags. This collection represents data received from other chares using the receive_data function.
Iterable actions can request that the algorithm be paused or halted for the current phase, and control which action in the current PDAL will be executed next. This is all done via the return value from the apply function. The apply function for iterable actions must return a Parallel::iterable_action_return_t which is a std::tuple<Parallel::AlgorithmExecution, std::optional<size_t>>. The first element of the tuple controls how algorithm execution continues. See the documentation of Parallel::AlgorithmExecution for the meanings of different values of that enum. The second element of the tuple is usually set to std::nullopt in order to continue iterating through the algorithm, but can be used to jump to a different action in the current PDAL. Most iterable actions will simply return
An action that pauses the algorithm will return
After an algorithm has been paused it can be restarted by passing false to the set_terminate method or by calling receive_data(..., true). Since the order in which messages are received is undefined in most cases the receive_data(..., true) call should be used to restart the algorithm.
The return value Parallel::AlgorithmExecution::Retry deserves special mention. It is intended for use by actions that use data supplied by other parallel objects to indicate that they have not received all of the data they require. The algorithm will stop until an operation that could supply data has occurred and then the action will be retried. An example of waiting because of missing data is
In order to jump to a specific action, the metafunction tmpl::index_of<list, element> can be used to get an tmpl::integral_constant with the value of the index of the element element in the typelist list. For example,
The metafunction call tmpl::index_of<ActionList, iterate_increment_int0>::value returns a size_t whose value is that of the action iterate_increment_int0 in the PDAL. The indexing of actions in the PDAL starts at 0.
Iterable actions are invoked as part of the algorithm and so the only way to request they be invoked is by having the algorithm run on the parallel component. The algorithm can be explicitly evaluated in a new phase by calling start_phase(Phase::TheCurrentPhase):
Alternatively, to evaluate the algorithm without changing phases the perform_algorithm() method can be used.
By passing true to perform_algorithm the algorithm will be restarted if it was paused.
The algorithm is also evaluated by calling the receive_data function, either on an entire array or singleton (this does a broadcast), or an on individual element of the array. Here is an example of a broadcast call:
and of calling individual elements:
The receive_data function always takes a ReceiveTag, which is set in the actions' inbox_tags type aliases. The inbox_tags must have two member type aliases, a temporal_id which is used to identify when the data was sent, and a type which is the type of the data to be stored in the inboxes. The types are typically a std::unordered_map<temporal_id, DATA>. In the discussed scenario of waiting for neighboring elements to send their data the DATA type would be a std::unordered_map<TheElementId, DataSent>. Inbox tags must also specify a static bool insert_into_inbox() function. For example,
The return value indicates whether perform_algorithm() should be called after insertion. This exists primarily to allow the communication logic used with DgElementArray to match that used with DgElementCollection more closely. It is safe to always return true.
For common types of DATA, such as a map, a data structure with an insert function, a data structure with a push_back function, or copy/move assignment that is used to insert the received data, inserters are available in Parallel::InboxInserters. For example, there is Parallel::InboxInserters::Map for map data structures. The inbox tag can inherit publicly off the inserters to gain the required insertion capabilities:
Any inbox tag that uses Charm++ messages must also specify a message_type type alias which is the object that will be sent. An example is:
The inbox_tags type alias for the action is:
An inbox tag can also optionally specify a static function called output_inbox that returns a std::string. This function can be used for printing the contents of the inbox in a nice way as the types can sometimes get complicated. You can also use the Parallel::output_inbox function to output a specific inbox from all the inboxes. See an above example for the signature of the output_inbox function.
- Warning
- It is the responsibility of the iterable action to remove data from the inboxes that will no longer be needed.
Normally when remote functions are invoked they go through the Charm++ runtime system, which adds some overhead. The receive_data function tries to elide the call to the Charm++ RTS for calls into array components. Charm++ refers to these types of remote calls as "inline entry methods". With the Charm++ method of eliding the RTS, the code becomes susceptible to stack overflows because of infinite recursion. The receive_data function is limited to at most 64 RTS elided calls, though in practice reaching this limit is rare. When the limit is reached the remote method invocation is done through the RTS instead of being elided.
3. Reduction Actions
Reduction actions are the targets of reducing data over an array. For example, you may want to know the sum of a int from every element in the array. You can do this as follows:
This reduces over the parallel component ArrayParallelComponent<Metavariables>, reduces to the parallel component SingletonParallelComponent<Metavariables>, and calls the action ProcessReducedSumOfInts after the reduction has been performed. The reduction action is:
As you can see, the last argument to the apply function is of type int, and is the reduced value.
You can also broadcast the result back to an array, even yourself. For example,
It is often necessary to reduce custom data types, such as std::vector or std::unordered_map. Charm++ supports such custom reductions, and so does our layer on top of Charm++. Custom reductions require one additional step to calling contribute_to_reduction, which is writing a reduction function to reduce the custom data. We provide a generic type that can be used in custom reductions, Parallel::ReductionData, which takes a series of Parallel::ReductionDatum as template parameters and ReductionDatum::value_types as the arguments to the constructor. Each ReductionDatum takes up to four template parameters (two are required). The first is the type of data to reduce, and the second is a binary invokable that is called at each step of the reduction to combine two messages. The last two template parameters are used after the reduction has completed. The third parameter is an n-ary invokable that is called once the reduction is complete, whose first argument is the result of the reduction. The additional arguments can be any ReductionDatum::value_type in the ReductionData that are before the current one. The fourth template parameter of ReductionDatum is used to specify which data should be passed. It is a std::index_sequence indexing into the ReductionData.
- Warning
- All elements of the array must call the same reductions in the same order. It is defined behavior to do multiple reductions at once as long as all contribute calls on all array elements occurred in the same order. It is undefined behavior if the contribute calls are made in different orders on different array elements.
4. Threaded Actions
Threaded actions are similar to simple actions, with the difference being that multiple threaded actions may be running on the same chare at the same time (potentially in parallel with one simple or reduction action). The apply function for a threaded actions has the same signature as that for a simple action, except that it also receives a NodeLock intended to control access to the chare's db::DataBox. All access to the db::DataBox, including read-only access, must occur while the action owns this lock. (Simple and reduction actions implicitly hold the lock for their entire execution.)
Threaded actions can only be run on nodegroup chares.
5. Local Synchronous Actions
There is limited ability to retrieve data held by another parallel component via a direct synchronous call. Unlike the above actions, the invocation of a synchronous action is precisely a call to a member function of another parallel component; therefore, these invocations will run to completion, and return their result before the calling code proceeds in execution.
Aside from being synchronous and being able to return data, local synchronous actions behave the same as threaded actions, except that they will only run on the chare of a nodegroup that is on the local node.
Local synchronous actions' apply functions follow a signature motivated by threaded actions, but take fewer arguments. This may be a bug.
Local synchronous actions must specify their return type in a return_type type alias. This is to help simplify the logic with the variant db::DataBox held by the parallel component.
An example of a definition of a local synchronous action:
And the corresponding invocation:
- Warning
- Say an action is being run on a component on a node where a mutable item in the GlobalCache is up-to-date. This action then calls another action on a different component on a different node. It is NOT guaranteed that this mutable item in the GlobalCache is up-to-date on this new node. It is up to the user to ensure the mutable item is up-to-date on whatever node they run an action on, even if it was up-to-date on the node that sent the message. The Mutable items in the GlobalCache section gives details about mutable GlobalCache items.
Mutable items in the GlobalCache
Most items in the GlobalCache are constant, and are specified by type aliases called const_global_cache_tags as described above. However, the GlobalCache can also store mutable items. Because of asynchronous execution, EXTREME care must be taken when mutating items in the GlobalCache, as described below.
A mutable item can be of any type, as long as that type is something that can be checked for whether it is "up-to-date". Here "up-to-date" means that the item can be safely used (even read-only) without needing to be mutated first. For example, a mutable item might be a function of time that knows the range of times for which it is valid; the mutable item is then deemed up-to-date if it will be called for a time within its range of validity, and it is deemed not up-to-date if it will be called for a time outside its range of validity. Thus the up-to-date status of a mutable item is determined by both the state of the item itself and by the code that wishes to use that item.
1. Specification of mutable GlobalCache items
Mutable GlobalCache items are specified by a type alias mutable_global_cache_tags, which is treated the same way as const_global_cache_tags for const items.
2. Use of mutable GlobalCache items
1. Checking if the item is up-to-date
Because execution is asynchronous, any code that uses a mutable item in the GlobalCache must first check whether that item is up-to-date. The information about whether an item is up-to-date is assumed to be stored in the item itself. For example, a mutable object stored in the GlobalCache might have type std::map<temporal_id,T> (for some type T), and then any code that uses the stored object can check whether an entry exists for a particular temporal_id. To avoid race conditions, it is important that up-to-date checks are based on something that is independent of the order of mutation (like a temporal_id, and not like checking the size of a vector).
To check an item, use the function Parallel::mutable_cache_item_is_ready, which returns a bool indicating whether the item is up-to-date. If the item is up-to-date, then it can be used. Parallel::mutable_cache_item_is_ready takes a lambda as an argument. This lambda is passed a single argument: a const reference to the item being retrieved. The lambda should determine whether the item is up-to-date. If so, it should return a default_constructed std::unique_ptr<Parallel::Callback>; if not, it should return a std::unique_ptr<Parallel::Callback> to a callback function that will be called on the next Parallel::mutate of that item. The callback will typically check again if the item is up-to-date and if so will execute some code that gets the item via Parallel::get.
For the case of iterable actions, Parallel::mutable_cache_item_is_ready typically uses the callback Parallel::PerformAlgorithmCallback. In the example below, the vector is considered up-to-date if it is non-empty. If the vector is not up-to-date, then when it becomes up-to-date the callback function will be invoked; in this case the callback function re-runs perform_algorithm(), which will call the same action again.
Note that Parallel::mutable_cache_item_is_ready is called on the local node and does no parallel communication.
2. Retrieving the item
The item is retrieved using Parallel::get just like for constant items. For example, to retrieve the item Tags::VectorOfDoubles:
Note that Parallel::get is called on the local node and does no parallel communication.
Whereas we support getting non-mutable items in the GlobalCache from a DataBox via db::get, we intentionally do not support db::get of mutable items in the GlobalCache from a DataBox. The reason is that mutable items should be retrieved only after a Parallel::mutable_cache_item_is_ready check, and being able to retrieve a mutable item from a DataBox makes it difficult to enforce that check, especially when automatically-executing compute items are considered.
3. Modifying a mutable GlobalCache item
To modify a mutable item, pass Parallel::mutate two template parameters: the tag to mutate, and a struct with an apply function that does the mutating. Parallel::mutate takes two arguments: a reference to the local GlobalCache, and a tuple that is passed into the mutator function. For the following example,
the mutator function is defined as below:
Parallel::mutate broadcasts to every node, where it calls the mutator function and then calls all the callbacks that have been set on that node by Parallel::mutable_cache_item_is_ready. The Parallel::mutate operation is guaranteed to be thread-safe without any further action by the developer so long as the item being mutated can be mutated in a threadsafe way. See the Parallel::GlobalCache docs for more details.
Charm++ Node and Processor Level Initialization Functions
Charm++ allows running functions once per core and once per node before the construction of any parallel components. This is commonly used for setting up error handling and enabling floating point exceptions. Other functions could also be run. Which functions are run on each node and core is set by calling Parallel::charmxx::register_init_node_and_proc in CkRegisterMainModule() with function pointers to the functions to be called. For example: